สถาบันวิจัยปัญญาประดิษฐ์ประเทศไทย ได้ทำการเปิดชุดข้อมูลคู่ประโยคในภาษาอังกฤษ-ไทย จำนวนกว่า 1 ล้านคู่ประโยคสู่สาธารณะ โดยได้รับการสนับสนุนจาก SCB ภายใต้ชื่อ scb-mt-en-th-2020 ชุดข้อมูลคู่ประโยคนี้ ได้รวบรวมจากหลายข้อมูลแหล่งอาทิเช่น ประโยคจากบทสนทนา ข้อมูลจากเว็บไซต์ข่าวหรือองค์กรที่มีเนื้อหาในสองภาษา บทความวิกิพีเดีย และ เอกสารราชการ
การได้มาซึ่งคู่ภาษามีทั้ง การจ้างนักแปลภาษา และ การใช้ Algorithm ในจับคู่ประโยคภาษาไทยและอังกฤษโดยอัตโนมัติ (Sentence alignment) จากหน้าเอกสาร บทความ และเว็บไซต์
โดยชุดข้อมูลนี้ เป็น Model-ready หรือ พร้อมสำหรับการนำไปใช้ฝึกฝนโมเดลแปลภาษาได้ทันที ทางสถาบันฯ ได้เปิด Pre-trained model สำหรับการนำไปใช้งาน และเป็น Baseline model (สามารถดูเพิ่มเติมที่ Thai-English Machine Translation Model)
นอกจากนี้การสร้างชุดข้อมูล scb-mt-en-th-2020 ยังทำให้ทางสถาบันฯ ได้ชุดข้อมูลอื่นๆ ที่พร้อมจะนำไปแก้โจทย์ด้าน NLP อื่นๆ ดังนี้
- คุณภาพการแปลประโยคจากอังกฤษเป็นภาษาไทย
- การตัดแบ่งประโยคภาษาไทย
- การ Paraphrase ประโยคภาษาไทย
- การคัดแยกคะแนนที่ได้รับจากรีวิวสินค้าในภาษาไทย
สถิติชุดข้อมูล
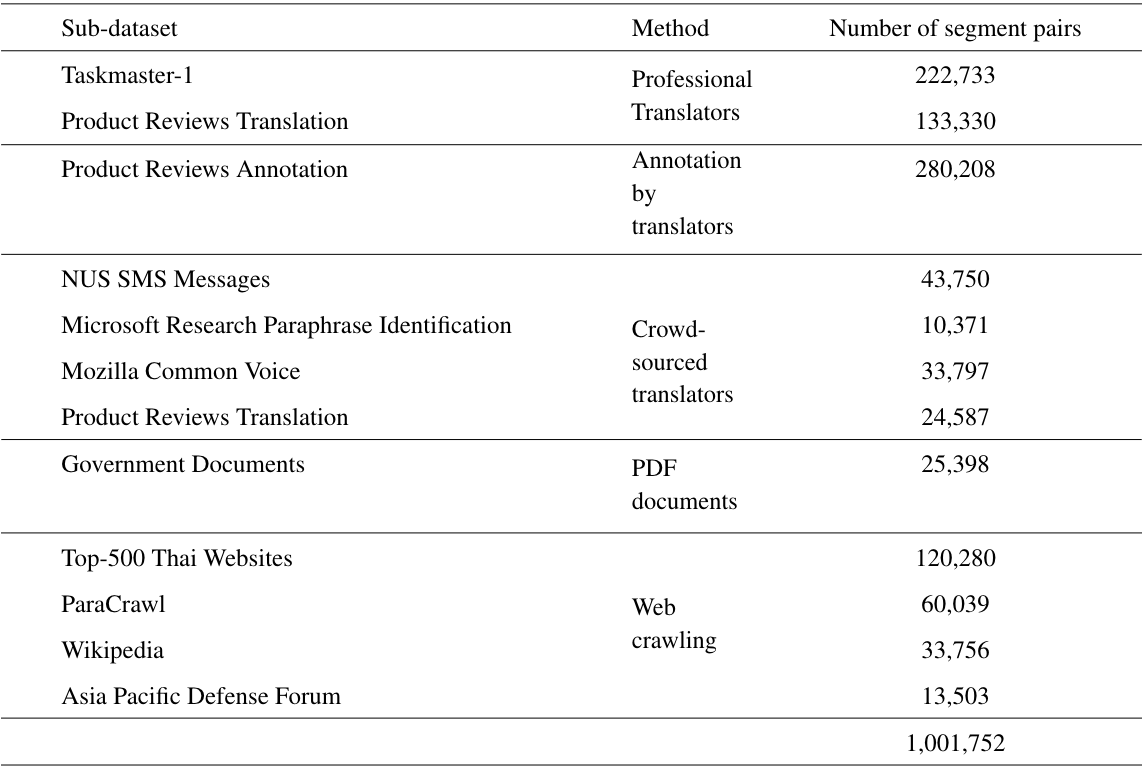
ตาราง 1: จำนวนคู่ประโยคในภาษาอังกฤษ-ไทย แบ่งตาม แหล่งที่มาของข้อมูลและวิธีการจับคู่ประโยค รวมจำนวนคู่ประโยคทั้งหมดคือ 1,001,752 คู่ประโยค
แหล่งที่มา
สำหรับแหล่งที่มาของชุดข้อมูลคู่ประโยค มีดังนี้
- ชุดข้อมูลด้าน NLP จากต่างประเทศที่เผยแพร่สู่สาธารณะ โดยชุดข้อมูลที่นำมาใช้จะ ประกอบด้วย ชุดข้อมูลบทสนทนา (Taskmaster-1 [Byrne et al. 2019]), ชุดข้อมูลข้อความ SMS จากผู้ใช้ในสิงค์โปร์ (NUS SMS [Chen et al. 2013]) ชุดข้อมูลการ Paraphrase ประโยค (Microsoft Research Paraphrase Identification [Dolan et al. 2005]) แล้วชุดข้อมูลประโยคสำหรับโจทย์ Automatic Speech Recognition (ASR) จาก Mozilla Common Voice
- การใช้โมเดล Text Generation เพื่อสร้างรีวิวสินค้าในภาษาอังกฤษ โดยทางสถาบันฯ ได้ทำการสร้างรีวิวสินค้าในภาษาอังกฤษ จากโมเดล Conditional Transformer Language Model for Controllable Generation (CTRL) [Keskar et al. 2019] ซึ่งเป็นโมเดลสำหรับ การสร้างข้อความขึ้นมาใหม่ โดยสามารถกำหนดบริบทหรือรูปแบบของข้อความที่จะสร้างได้
- การเก็บข้อมูลจากหน้าเว็บไซต์ที่มีเนื้อหาในสองภาษา โดยอิงจากโดเมนภาษาไทยที่ถูกจัดอันใน alexa.com 500 อันดับแรก และโดเมนที่อยู่ในชุดข้อมูล ParaCrawl Corpus [Esplà-Gomis et al. 2015] ซึ่งเป็นชุดข้อมูลที่รวบรวมเว็บไซต์ ที่มีเนื้อหาในภาษาอังกฤษและภาษาที่ใช้ในกลุ่มประเทศสมาชิกสหภาพยุโรป (EU)
- เอกสารราชการที่มีเนื้อหาทั้งภาษาไทยและอังกฤษ อาทิเช่น แผนพัฒนาการเศรษฐกิจและสังคมแห่งชาติ ประมวลกฎหมายแพ่งและพาณิชย์
- บทความจากวิกิพีเดียในภาษาไทยและภาษาอังกฤษ ที่มีเนื้อหาในหัวข้อเดียวกัน
ระเบียบวิธี
การจ้างนักแปลภาษาโดยตรง
สำหรับการจ้างแปลโดยตรง จะเป็นการแปล จากชุดข้อมูล Taskmaster-1 และ ชุดข้อมูลรีวิวสินค้าที่ถูกสร้างจาก โมเดล CTRL
นักแปลจาก Crowdsourcing platform
สำหรับการจ้างแปลจาก Crowdsourcing platform จะเป็นการแปล จากชุดข้อมูล NUS SMS, Microsoft Research Paraphrase Identidication, Mozilla Common Voice และ ชุดข้อมูลรีวิวสินค้า
การจ้างนักแปลเพื่อทำการยืนยันความถูกต้องจากผลการแปล จาก Google Translation API
สำหรับวิธีนี้ ทางสถาบันฯ ให้นำรีวิวสินค้า ส่วนหนึ่งจะส่งต่อไปยัง Google Translation API เพื่อทำการแปลเป็นภาษาไทยแล้วจึง ให้นักแปลยินยันความถูกต้องและความครบถ้วนของเนื้อหาจากผลการแปล
การใช้ Algorithm ในการจับคู่ประโยคในภาษาอังกฤษ-ไทย จาก ข้อมูลที่ได้จากการ crawl เว็บไซต์ บทความวิกิพีเดีย และ เอกสารราชการ
การจับคู่ประโยค ในส่วนของข้อมูลจากการ Crawl และ เอกสารราชการนั้น จะเป็นการจับคู่เอกสาร บทความ และ หน้าเว็บไซต์ก่อน (Document alignment or URL alignment) แล้วจึงทำการจับคู่ประโยค (Sentence alignment)
การตรวจคุณภาพ
สำหรับ การแปลจากการจ้างนักแปลโดยตรง จะมีทีมนักแปลที่ทำหน้าที่ตรวจสอบคุณภาพการแปล แต่ในส่วนของการ Crawl ข้อมูลนั้น จะมีความผิดพลาดในการการจับคู่ประโยคสูง ทางสถาบันฯ ได้ใช้ โมเดล Universal Sentence Encoder Multilingual [Cer et al. 2018] ในการคำนวณหาการแปลที่ตรงกันระหว่างประโยคภาษาอังกฤษและไทย และคัดกรองเอาคู่ประโยคไม่ได้จับคู่กันอย่างถูกต้องออก สำหรับวิธีการใช้ Universal Sentence Encoder Multilingual สามารถดูเพิ่มเติมได้จากบทความ ตรวจสอบความถูกต้องของการแปล ด้วย Universal Sentence Encoder
เวอร์ชัน
- Version 1.0 (23 June 2020): ชุดข้อมูลคู่ประโยคในภาษาอังกฤษ-ไทย จำนวน 1,001,752 คู่ประโยค
อ้างอิง
- Byrne, B., Krishnamoorthi, K., Sankar, C., Neelakantan, A., Goodrich, B., Duckworth, D., … & Cedilnik, A. (2019). Taskmaster-1: Toward a Realistic and Diverse Dialog Dataset. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) (pp. 4506-4517).
- Tao Chen and Min-Yen Kan (2013). Creating a Live, Public Short Message Service Corpus: The NUS SMS Corpus. Language Resources and Evaluation, 47(2)(2013), pages 299-355.
- Dolan, W.B., & Brockett, C. (2005). Automatically Constructing a Corpus of Sentential Paraphrases. IWP@IJCNLP.
- Esplà-Gomis, M., Forcada, M.L., Ramírez-Sánchez, G., & Hoang, H. (2019). ParaCrawl: Web-scale parallel corpora for the languages of the EU. MTSummit.
- Keskar, N.S., McCann, B., Varshney, L.R., Xiong, C., & Socher, R. (2019). CTRL: A Conditional Transformer Language Model for Controllable Generation. ArXiv, abs/1909.05858.
- Cer, D.M., Yang, Y., Kong, S., Hua, N., Limtiaco, N., John, R.S., Constant, N., Guajardo-Cespedes, M., Yuan, S., Tar, C., Sung, Y., Strope, B., & Kurzweil, R. (2018). Universal Sentence Encoder. ArXiv, abs/1803.11175.
ผู้สนับสนุน และเงื่อนไขการใช้งาน
![]()
บมจ. ธนาคารไทยพาณิชย์ ได้ทำการบริจาคชุดข้อมูลนี้ให้แก่สาธารณะ ภายใต้เงื่อนไขลิขสิทธิ์แบบครีเอทีฟคอมมอนส์ แสดงที่มา-อนุญาตแบบเดียวกัน 4.0 International (CC BY-SA 4.0) ยกเว้นชุดข้อมูลคู่ประโยคภาษาอังกฤษ-ไทย จาก Mozilla Common Voice จะไม่สงวนลิขสิทธิ์ (CC0; No Rights Reserved)