สถาบันวิจัยปัญญาประดิษฐ์ประเทศไทย ได้ทำการเทรนโมเดลแปลภาษา (Machine Translation) สำหรับการแปลภาษาใน 2 คู่ภาษา ไทย→อังกฤษ และ อังกฤษ→ไทย จากชุดข้อมูลคู่ประโยคในภาษาอังกฤษ-ไทย (scb-mt-en-th-2020) ซึ่งมีจำนวนกว่า 1 ล้านคู่ประโยค และได้วัดประสิทธิภาพของโมเดลด้วย BLEU score กับข้อมูลชุดทดสอบจาก The International Conference on Spoken Language Translation (IWSLT) ในปี 2015 ซึ่งเป็น คู่ประโยค อังกฤษ-ไทย ที่ได้จากการถอดคำพูด (Transcription) จาก TED Talk จากผลการทดสอบพบว่า โมเดลแปลภาษาสำหรับ ภาษาไทย→อังกฤษ (SCB_1M-MT_OPUS+TBASE) และ ภาษาอังกฤษ→ไทย (SCB_1M-MT_OPUS+TBASE) สามารถแปลภาษาได้มีประสิทธิภาพเทียบเท่าหรือดีกว่าระบบแปลภาษาจาก Google Translation API (ทดสอบ ณ เดือนพฤษภาคม 2020)
Transformer
Transformer [Vaswani et al. 2017] เป็นโมเดลประเภท Sequence-to-Sequence ที่ออกแบบสำหรับการสร้างโมเดลแปลภาษา ซึ่ง Transformer นั้นถือว่า มีความแม่นยำสูงที่สุด ในปัจจุบัน (ปี 2020) อ้างอิงจากชุดข้อมูลทดสอบจาก จากงานประชุมทางวิชาการ Workshop on Statistical Machine Translation ปี 2013 (WMT2013) ในคู่ภาษา อังกฤษ→เยอรมัน
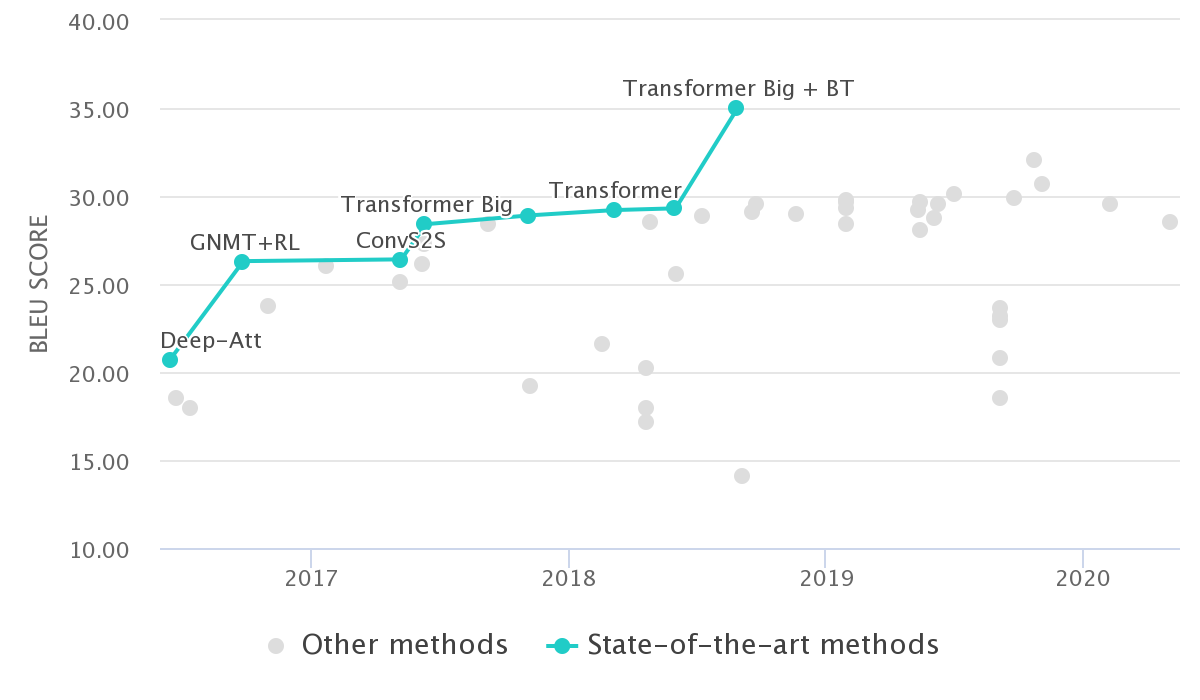
รูป 1: การวัดผลโมเดลแปลภาษาใน Architecture ต่างๆ บนชุดข้อมูลทดสอบจากงานประชุมวิชาการ WMT ในปี 2013 สำหรับคู่ภาษา อังกฤษ→เยอรมัน (WMT2013 en-de) ในช่วงระหว่างปี 2016 - 2020 (ข้อมูลจาก paperwithcode.com)
สำหรับการเทรนโมเดลนั้น ทางทีมวิจัย ได้เทรนโมเดล Transformer แบบ Base ซึ่งมีจำนวนพารามิเตอร์ทั้งหมดกว่า 74 ล้านพารามิเตอร์ และใช้ Python library fairseq จาก Facebook AI Research [Ott et al. 2019] โดยเทรนโมเดลบน NVIDIA DGX-1 ซึ่งเป็น Cluster ของ GPU NVIDIA V100
ชุดข้อมูลที่ใช้ในการเทรนโมเดลครั้งนี้มาจาก ชุดข้อมูลคู่ประโยคภาษาอังกฤษ-ไทย (scb-mt-en-th-2020) ซึ่งมีจำนวน 1,001,752 คู่ประโยค จากแหล่งที่มาต่างๆเช่น การจ้างนักแปลภาษา แปลบทสนทนาจากภาษาอังกฤษเป็นไทย และการ Crawl ข้อมูลจากเว็บไซต์ข่าวหรือองค์กร ที่มีเนื้อหาในทั้งสองภาษา โดยสามารถดูรายละเอียดเพิ่มเติมได้ที่ English-Thai Machine Translation Dataset
ผลการทดสอบ
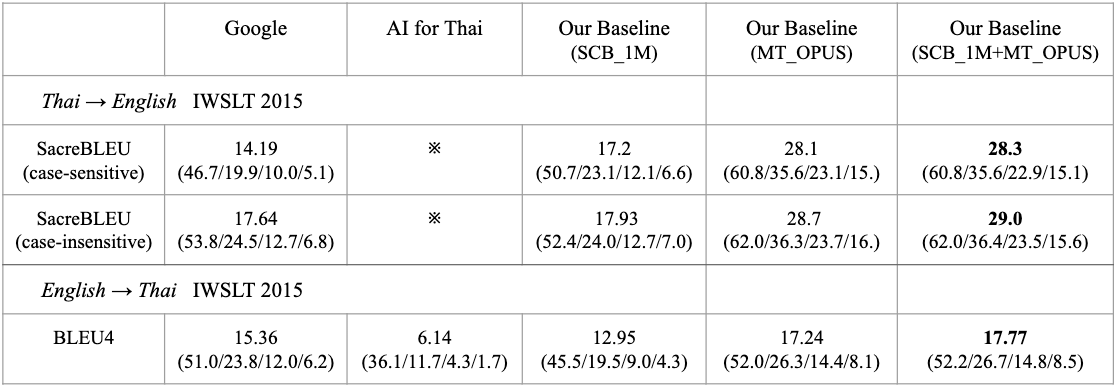
การเปรียบเทียบ BLEU score และ n-gram precision ระหว่าง ผลการแปลของโมเดล Transformer Base ที่เทรนจาก ชุดข้อมูลคู่ประโยคจาก scb-mt-en-th-2020 (SCB_1M), ชุดข้อมูลคู่ประโยคจาก Open Parallel Corpus [Tiedemann et al. 2012] ในส่วนที่เป็นคู่ประโยคภาษาอังกฤษและไทย (mt-opus), ชุดข้อมูลคู่ประโยคที่รวมทั้ง scb-mt-en-th-2020 และ mt-opus (SCB_1M + MT_OPUS), ผลการแปลของโมเดลแปลภาษาเฉพาะการแปลจากอังกฤษ→ไทย จาก AI for Thai (aiforthai.in.th) และ ผลการแปลจาก Google Translation API (ทดสอบและวัดผลใน เดือนพฤษภาคม 2020)
สำหรับคู่ประโยคทีใช้ทดสอบ เป็นชุดข้อมูลทดสอบจาก IWSLT 2015 ประกอบด้วย 46 Transcript ที่มีการถอดคำและแปลในภาษาอังกฤษและไทย จาก TED Talk ระหว่างปี 2010 ถึง 2013 (tst2010-2013) รวมเป็น 4,242 ประโยค โดยใช้ SacreBLEU [Post et al. 2018] (case sensitive / case-insentive) สำหรับภาษาอังกฤษเป็น Target language และ BLEU4 [Papineni et al. 2002] สำหรับภาษาไทยเป็น Target language
ตัวอย่างการใช้ในภาษา Python
from fairseq.models.transformer import TransformerModel
MODEL_BASE_DIR = './SCB_1M+TBASE_th-en_spm-spm_32000-joined_v1.0/models/'
VOCAB_BASE_DIR = './SCB_1M+TBASE_th-en_spm-spm_32000-joined_v1.0/vocab/'
BPE_BASE_DIR = './SCB_1M+TBASE_th-en_spm-spm_32000-joined_v1.0/bpe/'
th2en = TransformerModel.from_pretrained(
model_name_or_path=MODEL_BASE_DIR,
checkpoint_file='checkpoint.pt',
data_name_or_path=VOCAB_BASE_DIR,
bpe='sentencepiece',
sentencepiece_vocab=BPE_BASE_DIR + 'spm.th.model')
th2en.translate("งั้นเอาเป็นเวนติ แบล็คแอนด์ไวท์มอคค่าใส่นมสดกับวิปครีม จากสตาร์บัคส์สาขาห้างเบิร์ชวิลล์นะคะ")
Output:
so a venti black and white mocha with whole milk
and whipped cream from the starbucks at the birchville mall.
นอกจากนี้ทางสถาบันฯ ได้เตรียม Jupyter Notebook สำหรับการทดสอบการรันโมเดล Machine Translation ได้โดยทันทีผ่าน Google Colaboratory
เวอร์ชัน
- Version 1.0 (23 June 2020): โมเดล Pre-trained Transformer Base ที่เทรนจาก ชุดข้อมูลคู่ประโยคภาษาอังกฤษ-ไทย
scb-mt-en-th-2020เวอร์ชั่น 1.0
อ้างอิง
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008).
- Ott, M., Edunov, S., Baevski, A., Fan, A., Gross, S., Ng, N., Grangier, D., & Auli, M. (2019). fairseq: A Fast, Extensible Toolkit for Sequence Modeling. NAACL-HLT.
- Tiedemann, J. (2012). Parallel Data, Tools and Interfaces in OPUS. LREC.
- Papineni, K., Roukos, S., Ward, T., & Zhu, W. J. (2002, July). BLEU: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting on association for computational linguistics (pp. 311-318). Association for Computational Linguistics.
- Post, M. (2018). A Call for Clarity in Reporting BLEU Scores. WMT.
ทดลองแปลด้วยโมเดล
ข้อจำกัดของโมเดล และวิธีการแก้ไขเบื้องต้น
จากการทดสอบโมเดลแปลภาษาเบื้องต้น พบว่ามีข้อจำกัดบางประการที่เกิดขึ้นได้จากโมเดลแปลภาษา ดังนี้
การแปลข้อความที่มีหลายบรรทัด (multi-line sentences)
>> en2th.translate("The people creating an oasis with seawater\nBy Chloe Berge and Sunny Fitzgerald")
"ผู้คนสร้างโอเอซิสด้วยน้ําทะเล By Chloe Berge และ Sunny Fitzgerald"
แนวทางการแก้ไข: เนื่องจากการรับข้อมูลจาก Textbox ข้อความอาจจะประกอบด้วยหลายบรรทัด โดยมีการแบ่งด้วย \n ซึ่งอาจจะส่งผลให้ข้อความยาวเกินข้อจำกัดของโมเดลแปลภาษา หรือมีผลการแปลที่ไม่ถูกต้องได้ ผู้ใช้สามารถแยกข้อความตาม \n แล้วจึงส่ง List ของข้อความที่ถูกแบ่ง ไปยังโมเดล โดยผลการแปลจะคืนค่าเป็น List ของผลการแปล
>> text_input = "The people creating an oasis with seawater\nBy Chloe Berge and Sunny Fitzgerald"
>> segments = text_input.split("\n")
>> segments
[ "The people creating an oasis with seawater",
"By Chloe Berge and Sunny Fitzgerald"]
>> results = en2th.translate(segments)
>> results
["ผู้คนสร้างโอเอซิสด้วยน้ําทะเล",
"โดย Chloe Berge และ Sunny Fitzgerald"]
การแปลข้อความเปล่า หรือ empty string และโมเดลได้ให้ผลแปลที่ไม่ถูกต้อง ตัวอย่างเช่น
>> th2en.translate("")
"I don't think so."
>> en2th.translate("")
". ."
แนวทางการแก้ไข: ผู้ใช้สามารถระบุให้ข้อความที่เป็น empty string ไม่ส่งไปยังโมเดลแปลภาษา และให้คืนค่าเป็น empty string เหมือนเดิม
def translate_segment(text):
if len(text.strip()) == 0:
return ""
การแปลข้อความโดยที่ภาษาต้นทางของโมเดลไม่ตรงกัน เช่น การแปลด้วยโมเดล อังกฤษ→ไทย แต่ข้อความนำเข้าเป็นภาษาไทย
>> th2en.translate("ฉันอยากจองเที่ยวบินไปโตเกียว")
"I'd like to book a flight to Tokyo."
>> en2th.translate("ฉันอยากจองเที่ยวบินไปโตเกียว") # ข้อความนำเข้าควรเป็นภาษาอังกฤษ
"ไล่ระดับสี"
แนวทางการแก้ไข: เนื่องจากโมเดลถูกเทรนแยกกันในการแปลระหว่าง อังกฤษ→ไทย และ ไทย→อังกฤษ ผู้ใช้งานสามารถกำหนดเงื่อนไขให้ของข้อความนำเข้าว่าควรเป็นข้อความในภาษาต้นทางที่โมเดลได้ถูกเทรนมา เพื่อป้องกันข้อผิดพลาดนี้
import re
def translate_en2th(text):
if re.search(r"ก-๙", text):
raise "Input text should be in English."
การแปลคำหนึ่งคำในภาษาอังกฤษอาจส่งผลให้โมเดลแปลผลได้ไม่ถูกต้อง
>> en2th.translate("method")
วิธีการ@ label
>> en2th.translate("methodology.")
กลไกComment
>> en2th.translate("cat")
แมวName
แนวทางการแก้ไข: ในบางกรณีการแปลคำหนึ่งคำอาจจะมีผลการแปลที่ไม่ถูกต้องได้ เนื่องจากชุดข้อมูลที่ใช้เทรนโมเดลมักจะเป็นในระดับประโยค การแก้ปัญหาเบื้องต้นสามารถทำได้โดยการเพิ่ม “.” ต่อท้ายข้อความนำเข้า แล้วจึงทำการ post-processing ด้วยการลบ “.” ที่ต่อท้ายผลการแปล
>> en2th.translate("method.")
วิธีการ.
>> en2th.translate("methodology.")
ระเบียบวิธี
>> en2th.translate("cat.")
แมว