สถาบันวิจัยปัญญาประดิษฐ์ประเทศไทย (Thailand Artificial Intelligence Research Institute) ได้ทำการเทรนโมเดลภาษา (language model) บนชุดข้อมูลในภาษาไทยที่ได้จากแหล่งต่างๆ เช่น ข่าว, วิกิพีเดีย, ข้อความในโซเชียลมีเดีย และข้อมูลที่ได้จากการ crawl เว็บไซต์ในอินเทอร์เน็ต ซึ่งมีขนาดข้อมูลรวม 78.5 GB และได้วัดประสิทธิภาพของโมเดลภาษาที่ finetune แล้ว ได้ผลคะแนน micro-averaged F1 score สูงที่สุดบน 5 ขุดข้อมูล จากทั้งหมด 6 ชุดข้อมูล โดยเป็นชุดข้อมูลทดสอบในโจทย์การจำแนกข้อความ (text classification) และการจำแนกคำ (token classifcation) เมื่อเทียบกับ baseline model และโมเดลภาษาแบบหลายภาษา (multilingual language model) ที่มีอยู่ในปัจจุบัน (mBERT และ XLMR)
โมเดลทางภาษาจาก Google AI Language และ Facebook AI Research
ในปี 2018 Google AI Language ได้ทำการเสนอวิธีการหนึ่งชื่อว่า BERT [Devlin et al., 2019] ที่จะนำโมเดลภาษา (language model) จากสถาปัตยกรรม Transformer [Vaswani et al., 2017] เฉพาะในส่วน encoder มาฝึกฝนบนชุดข้อมูลที่ไม่ผ่านการกำกับ (unannotated text) จากชุดข้อมูลวิกิพีเดียและชุดข้อมูลจากหนังสือที่ถูกตีพิมพ์ในภาษาอังกฤษ (BookCorpus) และได้นำโมเดลภาษานี้มา finetune บนโจทย์ด้านการประมวลผลภาษาธรรมชาติอื่นๆ เช่น text classification, NER/POS tagging, question answering การนำเสนอวิธีการนี้พบว่า BERT หลังจากการนำไป finetune แล้วได้คะแนนสูงสุดบน 8 ชุดข้อมูลทดสอบทางด้านการเข้าใจภาษาธรรมชาติในภาษาอังกฤษซึ่งเป็นส่วนหนึ่งของ GLUE (General Language Understanding Evaluation benchmark) [Wang et al., 2019] ได้คะแนนสูงสุดในโจทย์การถามตอบ (question answering) จากชุดข้อมูล SQuAD 1.1 และ SQuAD 2.0 และได้คะแนนสูงสุดในโจทย์การหาความสอดคล้องหรือขัดแย้งกันจากคู่ของประโยค จากชุดข้อมูล MultiNLI
ถัดมาในปี 2019 Facebook AI Research นำเสนอ เป็นเทคนิคการเทรนโมเดลภาษาให้มีประสิทธิภาพมากยิ่งขึ้น โดยใ้ช้ชื่อว่า RoBERTa [Liu et al., 2019] โดยเป็นการต่อยอดจาก BERT จากผลการทดลองพบว่าได้คะแนนสูงสุด บนชุดข้อมูล GLUE, SQuAD 1.1, SQuAD 2.0 และ MultiNLI โดยโมเดลที่ได้นั้นมีประสิทธิภาพสูงกว่า BERT
ข้อจำกัดของ Multilingual BERT และ RoBERTa กับภาษาไทย
เนื่องด้วยปัจจุบันโมเดลภาษาแบบหลายภาษา (multilingual language model) ที่รวมภาษาไทยในชุดเข้าไปอยู่ในชุดข้อมูลฝึกฝนด้วย (อาทิเช่น mBERT [Devlin et al., 2019] และ XLMR [Conneau et al., 2020]) ยังมีข้อจำกัดบางประการอาทิเช่น การฝึกฝนโมเดลจะต้องเรียนรู้บนช้อมูลในภาษาอื่นๆรวมกว่า 100 ภาษาพร้อมกันทำให้ไม่สามารถที่จะเจาะจงไปที่รูปแบบการใช้ภาษา หรือการเพิ่มความหลากหลายของหัวข้อที่ปรากฏในชุดข้อมูลของภาษาไทยโดยเฉพาะได้ (ตัวอย่างเช่น XLMR อาศัยชุดข้อมูลจากการ crawl เว็บไซต์เพียงแหล่งเดียว หรือ mBERT ที่อาศัยข้อมูลจากวิกิพีเดียเท่านั้น) ทาง AIResearch จึงได้เริ่มการเทรนโมเดลแบบภาษาเดียว (monolingual language model) บนชุดข้อมูลภาษาไทยขนาดกว่า 78.5 GB จากแหล่งข้อมูลต่างๆ โดยได้เลือกใช้วิธีการที่ชื่อ RoBERTa ในการเทรนครั้งนี้
วิธีการเทรนโมเดล WangchanBERTa
สำหรับการเทรนโมเดลนั้นจะใช้ objective คือ Masked Language Model (MLM) หรือการทำนายคำในประโยคที่ถูกแทนที่ด้วย masked token โดยชุดข้อมูลที่ใช้ในการเทรนโมเดล จะเป็นชุดข้อมูลจากแหล่งต่างๆ เช่น วิกิพีเดียภาษาไทย, ข่าวจากสำนักข่าวในประเทศไทย, โพสท์/คอมเมนต์จากสื่อโซเชียลมีเดีย, ซับไตเติ้ลจากโครงการ OpenSubtitles และชุดข้อมูลอื่นๆที่มีการเผยแพร่และเปิดข้อมูลสู่สาธารณะจะสำหรับการฝึกฝนโมเดลการประมวลผลภาษาไทยในโจทย์ต่างๆเช่น machine translation (เฉพาะส่วนที่เป็นภาษาไทย) , sentiment analysis, และ text classification รวมเป็นข้อมูลขนาด 78.5 GB โมเดลที่เทรนบนชุดมูลดังกล่าวจะอยู่ภายใต้ชื่อขึ้นต้นว่า wangchanberta-base-att นอกจากนี่ได้มีการเทรนโมเดลบนข้อมูลในเฉพาะส่วนที่มาจากวิกิพีเดียภาษาไทย (ภายใต้ชื่อขึ้นต้นว่า wangchanberta-base-wiki)
เนื่องด้วยการนำชุดข้อมูลเข้าสู่โมเดลเพื่อทำการทำนาย masked token จะต้องผ่านกระบวนการตัดแบ่งคำ (word tokenization) โดยการตัดแบ่งคำที่ใช้นั้นจะเป็น 4 รูปแบบการตัดแบ่งคำคือ
-
การตัดแบ่งหน่วยคำย่อย (subword-level tokenization) ด้วยไลบรารี่ SentencePiece [Kudo et al., 2018] (ใช้ชื่อย่อว่า
spm) โดยตัวตัดแบ่งหน่วยคำย่อยอาศัยข้อมูลทางสถิติของการปรากฏร่วมกันของตัวอักษรในชุดข้อมูลในการกำหนดขอบเขตของหน่วยคำย่อย -
การตัดแบ่งคำจาก dictionary ของคำในภาษาไทยด้วย maximal matching algorithm (ใช้ชื่อย่อว่า
newmm) ด้วยไลบรารี่ PyThaiNLP [Phatthiyaphaibun et al., 2016] -
การตัดแบ่งพยางค์ในภาษาไทย จาก dictionary ของพยางค์ในภาษาไทยด้วย maximal matching algorithm (ใช้ชื่อย่อว่า
syllable) ด้วยไลบรารี่ PyThaiNLP -
การตัดแบ่งคำจากโมเดล machine learning (ใช้ชื่อย่อว่า
sefr) จากบทความทางวิชาการชื่อ “Stacked Ensemble Filter and Refine for Word Segmentation” [Limkonchotiwat et al., 2020]

รูป 1: ภาพประกอบแสดงการตัดแบ่งคำ, พยางค์ และหน่วยคำย่อยจากโมเดลการตัดแบ่งตามหน่อยคำ, หน่วยคำย่อย, หน่วยพยางค์ และหน่วยตัวอักษร
โดยการเทรนโมเดลในชุดข้อมูลขนาด 78.5GB จะใช้ตัดแบ่งหน่วยคำย่อย (spm)และการเทรนโมเดลในชุดข้อมูลวิกิพีเดียภาษาไทยจะใช้ตัวตัดแบ่งคำในทั้ง 4 รูปแบบ
ในการเทรนโมเดลด้วย Nvidia DGX-1 ซึ่งประกอบด้วย GPU รุ่น Nvidia Tesla V100 ขนาด 32GB จำนวน 8 หน่วย ใช้เวลาประมาณ 125 วัน สำหรับการเทรนโมเดลจากชุดข้อมูล 78.5GB (wangchanberta-base-att) เป็นจำนวน 500,000 training steps (หรือเป็นการเทรนจำนวนประมาณ 5 รอบของชุดข้อมูลฝึกฝน หรือ 5 epochs)
และใช้เวลาอยู่ในช่วงระหว่าง 2-4 วัน สำหรับการเทรนโมเดลบนชุดข้อมูลากวิกิพีเดียภาษาไทย (wangchanberta-base-wiki) ในแต่ละรูปแบบของ token ที่เลือกใช้
การวัดผลโมเดล
การเปรียบเทียบ micro F1-score จากโมเดล WangchanBERTa ในรูปแบบต่างๆที่ finetune บน ชุดข้อมูลสำหรับโจทย์ multi-class sequence classification, multi-label sequence classification และ token classification โดยชุดข้อมูลที่นำมา finetune และเปรียบเทียบประสิทธิภาพโมเดลมีดังนนี้
Multi-class sequence classification
- Wisesight Sentiment Corpus (github): เป็นชุดมูลสำหรับการจำแนกอารมณ์จากข้อความ (sentiment analysis) จากข้อความในโซเชียลเน็ตเวิร์ค ว่ามีอารมณ์เป็นไปทางบวก, กลาง, ลบ หรือเป็นข้อความประเภทคำถาม
- Wongnai Reviews (github): เป็นชุดมูลสำหรับการจำแนกรีวิวร้านอาหารจากผู้ใช้บริการแพลทฟอร์ม Wongnai โดยจะมีการกำกับว่าผู้ใช้บริการรีวิวได้เขียนรีวิวพร้อมให้คะแนนร้านอาหารจำนวนกี่คะแนน (ระหว่าง 1 – 5 ดาว)
- English-Thai Generated Reviews (github, paper): เป็นชุดข้อมูล การจำแนกคะแนนจากรีวิวสินค้า ที่ถูกสร้างขึ้นด้วยโมเดล CTRL (machine-generated texts) เป็นภาษาอังกฤษแล้วแปลเป็นภาษาไทยด้วยคนและ Google Translate โดยจะมีการกำกับว่ารีวิวดังกล่าวเป็นรีวิวที่ได้มีการให้คะแนนต่อสินค่านั้นๆจำนวนกี่คะแนน (ระหว่าง 1 – 5 ดาว)
Multi-label sequence classificaion
- Prachathai67k (github): เป็นชุดข้อมูลข่าวจาก Prachathai.com ซึ่งเป็นโจทย์ประเภท multi-label classification โดยเป็นการกำกับว่า พาดหัวข่าวดังกล่าว จะอยู่ในหมวดหมู่ (tag) ของข่าวใดบ้าง โดยจะมีจำนวน 12 หมวดหมู่ เช่น ข่าวการเมือง, เศรษฐกิจ, ต่างประเทศ, สิ่งแวดล้อม, และ สิทธิมนุษยชน เป็นต้น โดยหนึ่งพาดหัวข่าวจะมีการกำกับหมวดหมู่ ได้มากกว่า 1 หมวดหมู่
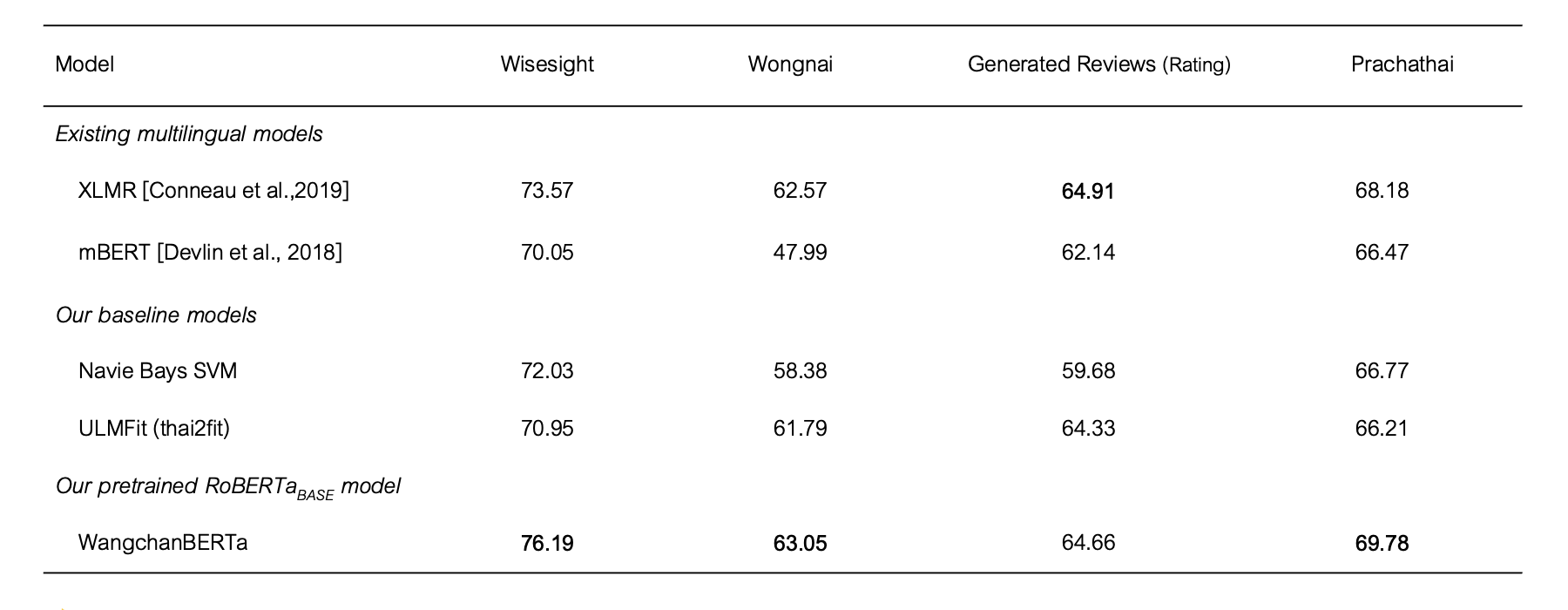
ตารางที่ 1: ผลการทดสอบบนชุดข้อมูลสำหรับโจทย์ sequence classification บนชุดข้อมูลทดสอบ (test set) โดยเกณฑ์ในการวัดผลคือ micro-averaged F1 score
Token classification
- ThaiNER (github): เป็นชุดข้อมูลการกำกับ หน้าที่ของคำ (Named-entity recognition; NER) ในภาษาไทย โดยมีจำนวน NER tags ทั้งหมด 13 ประเภท ชุดข้อมูลนี้รวบรวมโดยคุณ Wannaphong Phatthiyaphaibun ซึ่งเป็นการพัฒนาต่อจากชุดข้อมูลจาก คุณ Nutcha Tirasaroj [Tirasaroj and Aroonmanakun, 2011] จำนวน 2,258 ข้อความ
- LST20 (website, paper): เป็นชุดมูลสำหรับ การตัดแบ่งคำ, ประโยค, อนุประโยค, หน้าที่ของคำ และ นามจำเพาะ พัฒนาโดยศูนย์เทคโนโลยีอิเล็กทรอนิกส์และคอมพิวเตอร์แห่งชาติ (NECTEC) มีจำนวนการกำกับข้อความทั้งสิ้น 78,931 ข้อความ โดยในการทดลองนี้ได้ใช้โจทย์การกำกับ หน้าที่ของคำ (Part-of-speech; POS) และ การกำกับนามจำเพาะ (NER) โดยมีจำนวน tag สำหรับ POS 16 ประเภท และ สำหรับ NER 10 ประเภท
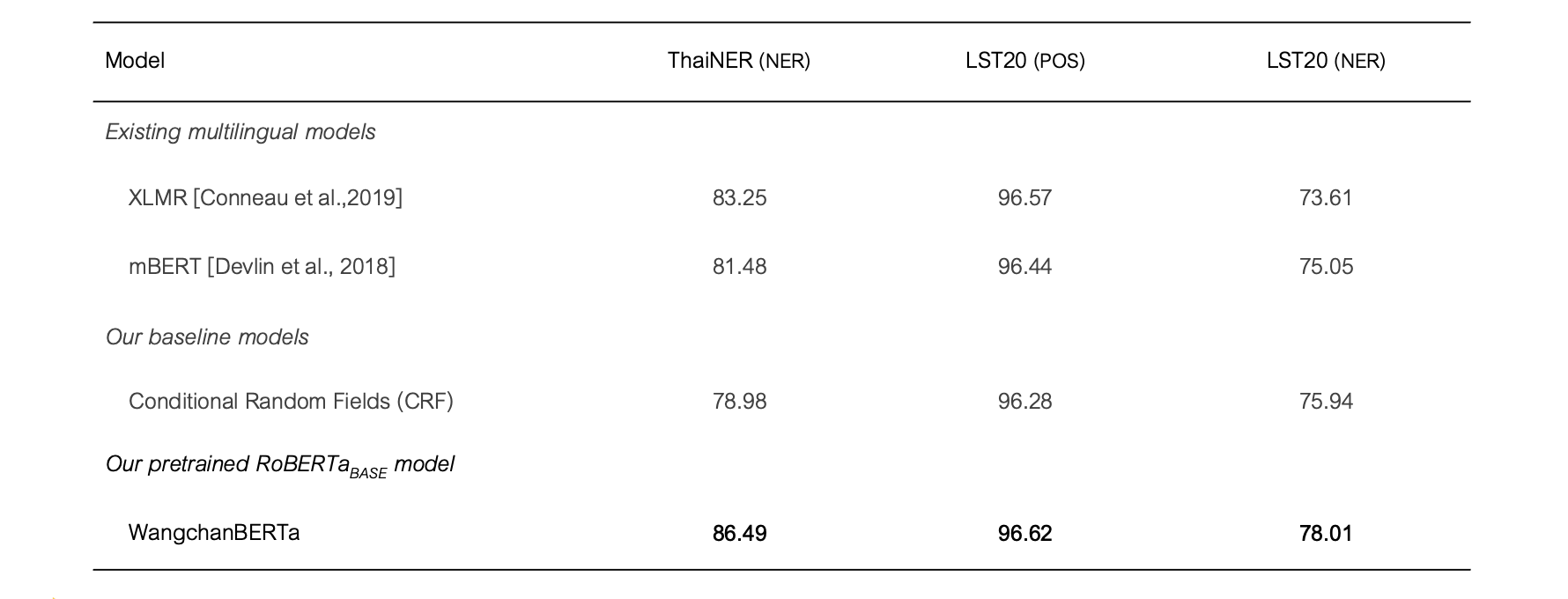
ตารางที่ 2: ผลการทดสอบบนชุดข้อมูลสำหรับโจทย์ token classification บนชุดข้อมูลทดสอบ (test set) โดยเกณฑ์ในการวัดผลคือ micro-averaged F1 score
ตัวอย่างการใช้ในภาษา Python
ติดตั้ง Python package ดังต่อไปนี้ transformers และ thai2transformers ด้วย pip
pip install transformers==3.5.1 thai2transformers==0.1.2
1. สำหรับการทำโจทย์ Masked Language Model (MLM)
from transformers import (
CamembertTokenizer,
AutoModelForMaskedLM,
pipeline
)
from thai2transformers.preprocess import process_transformers
# Load pre-trained tokenizer
tokenizer = CamembertTokenizer.from_pre-trained(
'airesearch/wangchanberta-base-att-spm-uncased',
revision='main')
tokenizer.additional_special_tokens = ['<s>NOTUSED', '</s>NOTUSED', '<_>']
# Load pre-trained model
model = AutoModelForMaskedLM.from_pre-trained(
'airesearch/wangchanberta-base-att-spm-uncased',
revision='main')
fill_mask = pipeline(task='fill-mask',
tokenizer=tokenizer,
model=model)
input_text = "โครงการมีระยะทางทั้งหมด 114.3 <mask> มีจำนวนสถานี 36 สถานี"
processed_input_text = process_transformers(input_text)
print(processed_input_text, '\n')
print(fill_mask(processed_input_text))
Output:
โครงการมีระยะทางทั้งหมด<_>114.3<_><mask><_>มีจำนวนสถานี<_>36<_>สถานี
[{'sequence': '<s> โครงการมีระยะทางทั้งหมด<_>114.3<_>กิโลเมตร <_>มีจํานวนสถานี<_>36<_>สถานี</s>',
'score': 0.9890820980072021,
'token': 1712,
'token_str': 'กิโลเมตร'},
{'sequence': '<s> โครงการมีระยะทางทั้งหมด<_>114.3<_>กม <_>มีจํานวนสถานี<_>36<_>สถานี</s>',
'score': 0.0037021981552243233,
'token': 2258,
'token_str': 'กม'},
{'sequence': '<s> โครงการมีระยะทางทั้งหมด<_>114.3<_>เมตร <_>มีจํานวนสถานี<_>36<_>สถานี</s>',
'score': 0.002338711405172944,
'token': 913,
'token_str': 'เมตร'
},
{'sequence': '<s> โครงการมีระยะทางทั้งหมด<_>114.3<_>กิโล <_>มีจํานวนสถานี<_>36<_>สถานี</s>',
'score': 0.0022131178993731737,
'token': 8017,
'token_str': 'กิโล'
},
{'sequence': '<s> โครงการมีระยะทางทั้งหมด<_>114.3<_>ไมล์ <_>มีจํานวนสถานี<_>36<_>สถานี</s>',
'score': 0.0013257935643196106,
'token': 6089,
'token_str': 'ไมล์'
}]
2. สำหรับการทำโจทย์ Sequence classification
from transformers import (
CamembertTokenizer,
AutoModelForSequenceClassification,
pipeline
)
from thai2transformers.preprocess import process_transformers
# Load pre-trained tokenizer
tokenizer = CamembertTokenizer.from_pre-trained(
'airesearch/wangchanberta-base-att-spm-uncased',
revision='main')
tokenizer.additional_special_tokens = ['<s>NOTUSED', '</s>NOTUSED', '<_>']
# Load pre-trained model
model = AutoModelForSequenceClassification.from_pre-trained(
'airesearch/wangchanberta-base-att-spm-uncased',
revision='finetuned@wisesight_sentiment')
classify_sequence = pipeline(task='sentiment-analysis',
tokenizer=tokenizer,
model=model)
input_text = "ฟอร์ด บุกตลาด อีวี ในอินเดีย #prachachat #ตลาดรถยนต์"
processed_input_text = process_transformers(input_text)
print(processed_input_text, '\n')
print(classify_sequence(processed_input_text))
input_text = "สั่งไป 2 เมนูคือมัชฉะลาเต้ร้อนกับไอศครีมชาเขียว มัชฉะลาเต้ร้อน รสชาเขียวเข้มข้น หอม มัน แต่ไม่กลมกล่อม มันจืดแบบจืดสนิท ส่วนไอศครีมชาเขียว ทานแล้วรสมันออกใบไม้ๆมากกว่าชาเขียว แล้วก็หวานไป โดยรวมแล้วเฉยมากก ดีแค่รสชาเขียวเข้ม มีน้ำเปล่าบริการฟรี"
processed_input_text = process_transformers(input_text)
print('\n', processed_input_text, '\n')
print(classify_sequence(processed_input_text))
Output:
ฟอร์ด<_>บุกตลาด<_>อีวี<_>ในอินเดีย<_>#prachachat<_>#ตลาดรถยนต์
[{'label': 'neu', 'score': 0.9879224896430969}]
สั่งไป<_>2<_>เมนูคือมัชฉะลาเต้ร้อนกับไอศครีมชาเขียว<_>มัชฉะลาเต้ร้อน<_>รสชาเขียวเข้มข้น<_>หอม<_>มัน<_>แต่ไม่กลมกล่อม<_>มันจืดแบบจืดสนิท<_>ส่วนไอศครีมชาเขียว<_>ทานแล้วรสมันออกใบไม้ๆมากกว่าชาเขียว<_>แล้วก็หวานไป<_>โดยรวมแล้วเฉยมากก<_>ดีแค่รสชาเขียวเข้ม<_>มีน้ำเปล่าบริการฟรี
[{'label': 'neg', 'score': 0.9252662062644958}]
3. สำหรับการทำโจทย์ Token classification
from transformers import (
CamembertTokenizer,
AutoModelForTokenClassification,
pipeline
)
from thai2transformers.preprocess import process_transformers
# Load pre-trained tokenizer
tokenizer = CamembertTokenizer.from_pre-trained(
'airesearch/wangchanberta-base-att-spm-uncased',
revision='main')
tokenizer.additional_special_tokens = ['<s>NOTUSED', '</s>NOTUSED', '<_>']
# Load pre-trained model
model = AutoModelForTokenClassification.from_pre-trained(
'airesearch/wangchanberta-base-att-spm-uncased',
revision='finetuned@thainer-ner')
classify_token = pipeline(task='ner',
tokenizer=tokenizer,
model=model,
grouped_entities=True)
input_text = "กสช. เตรียมทดลองประมููลคลื่น3จี 25 กค นี้"
processed_input_text = process_transformers(input_text)
print(processed_input_text, '\n')
print(classify_token(processed_input_text))
Output:
[{'entity_group': 'ORGANIZATION', 'score': 0.9989495873451233, 'word': ''},
{'entity_group': 'ORGANIZATION', 'score': 0.9986395835876465, 'word': 'ก'},
{'entity_group': 'ORGANIZATION', 'score': 0.9985694289207458, 'word': 'ส'},
{'entity_group': 'ORGANIZATION', 'score': 0.9982855916023254, 'word': 'ช'},
{'entity_group': 'ORGANIZATION', 'score': 0.9971947073936462, 'word': '.'},
{'entity_group': 'DATE', 'score': 0.9695429682731629, 'word': '25<_>กค<_>'}]
ทดลองใช้งานโมเดล
ทางสถาบันฯ ได้เตรียม Jupyter Notebook สำหรับการทดสอบการรันโมเดล ได้โดยทันทีผ่าน Google Colaboratory
สำหรับรายละเอียดของชุดข้อมูลที่ใช้และการเทรนโมเดลในแต่ละรูปแบบ ได้มีการอธิบายไว้ใน technical report
เวอร์ชัน
- เวอร์ชัน 1.0 (24 มกราคม 2021):
- โมเดล
wangcahbert-base-att-spm-uncasedที่เทรนบนชุดข้อมูลขนาด 78.5 GB ที่ checkpoint 360,000 - โมเดล
wangcahbert-base-wiki-spmที่เทรนบนชุดข้อมูลจากวิกิพีเดียภาษาไทย ที่ checkpoint 7,000 - โมเดล
wangcahbert-base-wiki-newmmที่เทรนบนชุดข้อมูลจากวิกิพีเดียภาษาไทย ที่ checkpoint 5,000 - โมเดล
wangcahbert-base-wiki-syllableที่เทรนบนชุดข้อมูลจากวิกิพีเดียภาษาไทย ที่ checkpoint 8,000 - โมเดล
wangcahbert-base-wiki-sefrที่เทรนบนชุดข้อมูลจากวิกิพีเดียภาษาไทย ที่ checkpoint 4,500 - โมเดล
bert-base-multilingual-casedที่นำมา finetune บน downstream task โดยเลือกจาก checkpoint ที่ได้คะแนน micro-averaged F1 score สูงที่สุด - โมเดล
xlm-roberta-baseที่นำมา finetune บน downstream task โดยเลือกจาก checkpoint ที่ได้คะแนน micro-averaged F1 score สูงที่สุด
- โมเดล
อ้างอิง
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. & Polosukhin, L. (2017). Attention is all you need. In Advances in Neural Information Processing Systems (pp. 5998-6008).
- Devlin, J., Chang, M., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the NAACL Volume 1 (pp. 4174-4186)
- Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., & Bowman, S.R. (2018). GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. BlackboxNLP@EMNLP.
- Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., & Stoyanov, V. (2019). RoBERTa: A Robustly Optimized BERT Pretraining Approach. ArXiv, abs/1907.11692.
- Conneau, A., Khandelwal, K., Goyal, N., Chaudhary, V., Wenzek, G., Guzmán, F., Grave, E., Ott, M., Zettlemoyer, L., & Stoyanov, V. (2020). Unsupervised Cross-lingual Representation Learning at Scale. ACL.
- Kudo, T., & Richardson, J. (2018). SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing. EMNLP.
- Limkonchotiwat, P., Phatthiyaphaibun, W., Sarwar, R., Chuangsuwanich, E., & Nutanong, S. (2020). Domain Adaptation of Thai Word Segmentation Models using Stacked Ensemble. EMNLP.
- Phatthiyaphaibun, W., Chaovavanich, K., Polpanumas, C., Suriyawongkul, A., Lowphansirikul, L., & Chormai, P. (2016, Jun 27). PyThaiNLP: Thai Natural Language Processing in Python. Zenodo. http://doi.org/10.5281/zenodo.3519354